
June 27, 2025
Data Cleansing, Standardization & Enrichment
A critical phase in a data project is data cleansing, de-duplication, standardization, enrichment including Address Enrichment, which entails finding and fixing mistakes or inconsistencies in the information to guarantee data dependability and quality. This is the phase where all data professionals spend most of their time.
Data errors, missing values, null values, duplicate data, redundant data, and improper data types must all be identified after the data collection stage.
The problem statement and business outcome must be taken into consideration when handling the data cleansing and modification process. This requires a set of activities to be undertaken by cross-functional team from different business functions, as below –
- Evaluating current data health
- Imputing empty values
- De-Duplication
- Identifying group of duplicate records
- Recommending Best record among the group of values
- Standardization
- Enrichment
- Address
- Web-Scraping
- Generating JSON
- Activation of processed record
These are regular steps required for achieving clean, sanitized and consistent data.
Let us see how these steps are performed in AI-assisted manner from DataC, a product from AccelSoft :
Data Sources – DataC supports fetching data from all the leading Database or from Files. Currently files support up to 50 columns to be processed effectively. Extension of number of columns can be incorporated based on customer specific requirements.
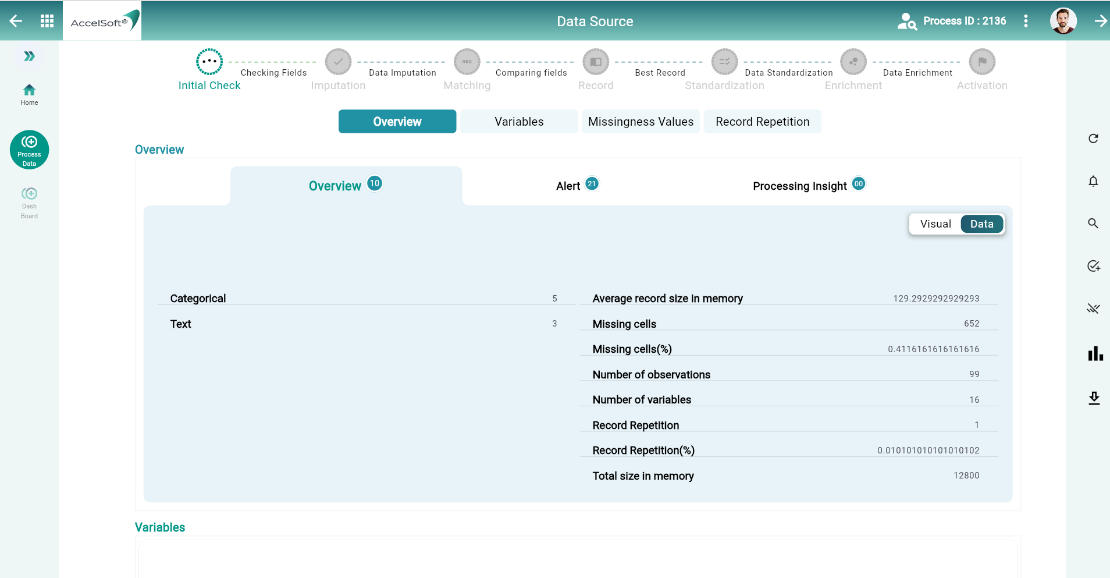
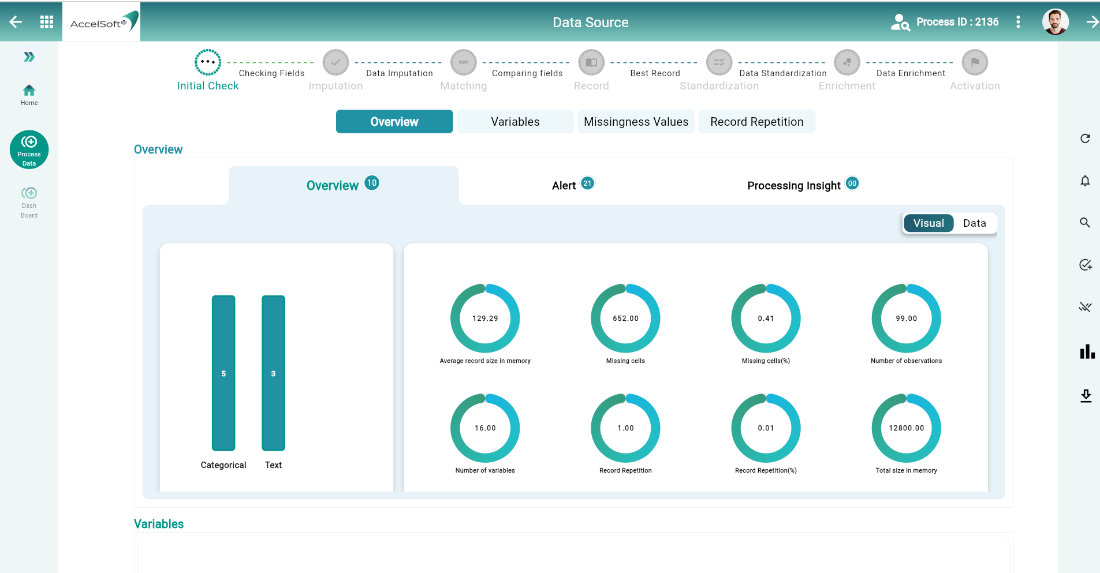
1. Evaluating current data health
- DataC analyses the data for it’s current health status with the help of many AI algorithms. You would get many details and that too in either data or visualization format.
Now that you are aware of what is required to sanitize or improvise data quality, you need to take action. You would proceed with below steps to accomplish –
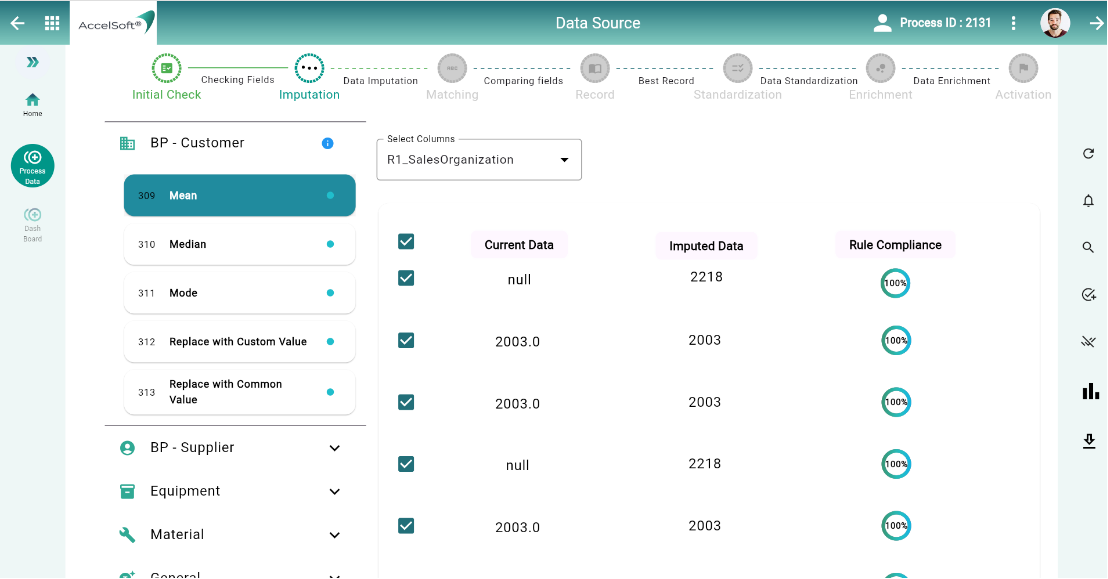
2. Imputing empty values
- You found many of the columns having blank or space as values however your insights may be lost if some of those are not having values. For example, education qualification, location, etc if left blank or carries random values. We easily understand the importance of imputing certain values into these (or, similar) columns so that data would be relevant.
DataC here plays a helping hand and provides options of imputing values individually or in mass – say one column in one go. Users gets options for –
- Numeric Values – to impute by Mean, Median, Average, Highest, Lowest, etc.
- String values – to impute by Constant, selecting value from other Row, etc.
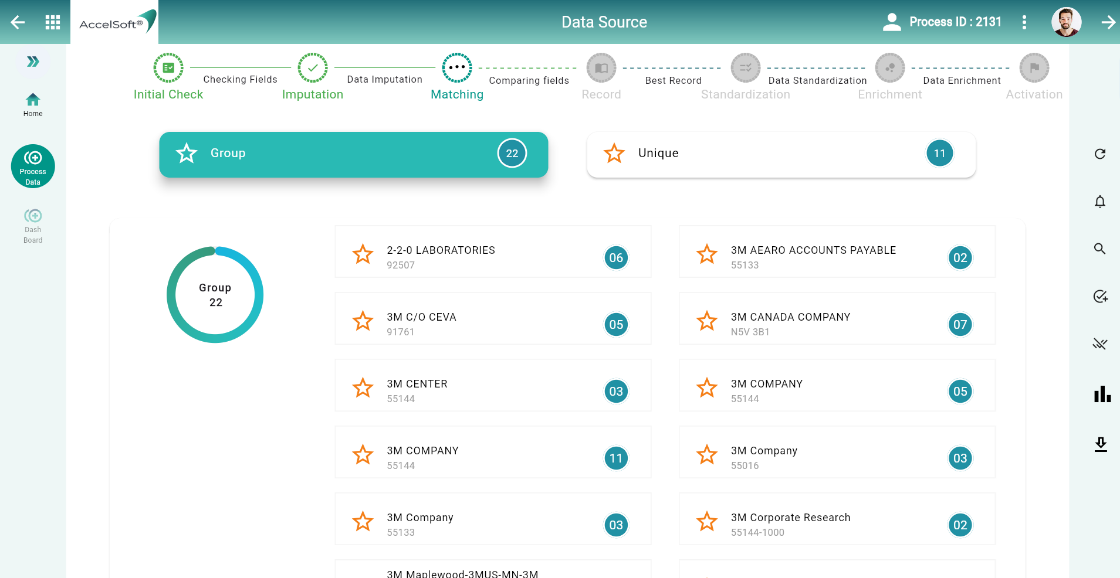
3. De-Duplication
A. Identifying group of duplicate records – DataC applies AI-algorithms and clubs all potential duplicates into groups. Here, our out of box AI-Model works however User has flexibility to define their own Model as per their own business needs as well.
Various ways to remove outliers –
- After identifying outliers through AI-Model, you can choose to remove them based on the visual representation of the data, such as box plots or scatter plots.
- Identify outliers based on the interquartile range. Data points outside a specified range (e.g., 1.5 times the IQR) can be removed.
- Calculate the Z-scores for each data point and remove those that fall above or below a certain threshold (e.g., Z > 3 or Z < -Z-scores measure how many standard deviations a data point is from the mean.
B. Recommending Best record among the group of values – DataC recommends Best Record based on AI-Model predictions. Users still have the choice to overrule that recommendation and go with what she believes is right based on their experience. Once approved as best-record, that same would be leveraged for further processing steps to get cleansed record.
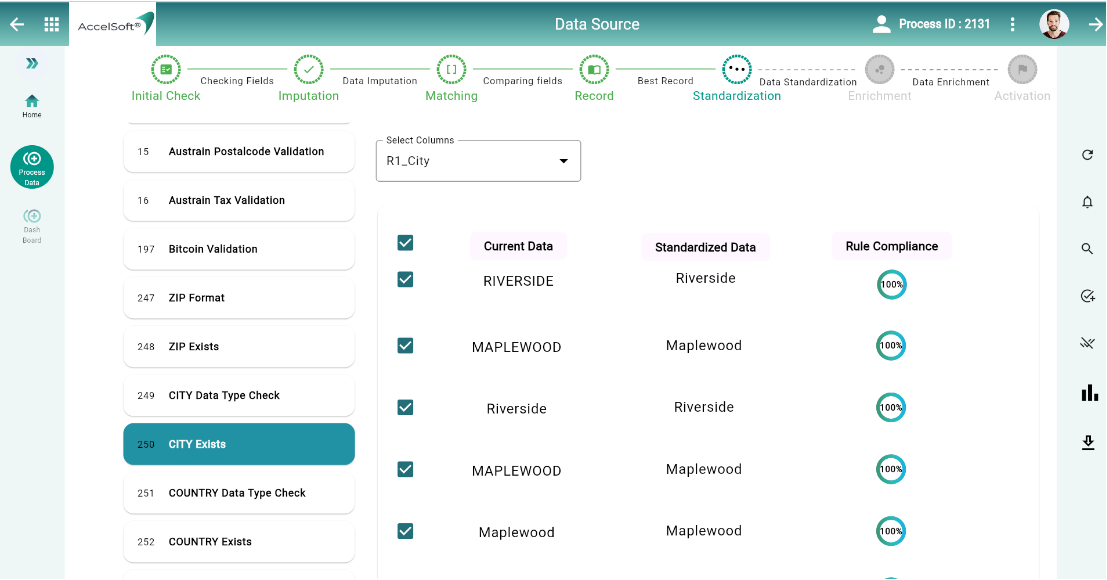
4. Standardization
DataC comes with many preconfigured business rules for achieving standardization. Just to illustrate – Finance has around 1800 rules, Business Partner (especially Customer or Vendor) has around 600 rules. Likewise, other objects also comes with certain prevalent business rules respectively. This helps you to standardize your data effectively.
AccelSoft’s low-code, no-code platform provides Business users a choice to add their Business specific Rules from the console (low-code limited to put business logic alone), DataC would convert those into API (no-code). With simple config step, the newly created rule would also be available for application on data cleansing process.
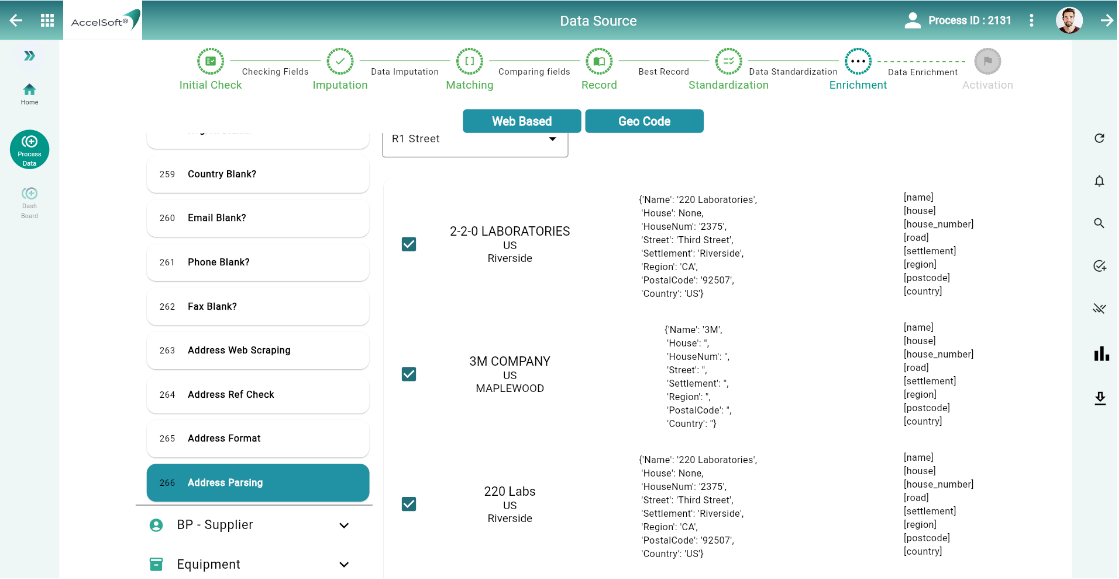
5. Enrichment
By far, data has largely been cleansed, de-duplicated and standardized. Now, Address comes into prominence. DataC recommends ISO standard for country-specific address-format. To add to that, it formats the address in ISO-compliant manner.
A. Address
- Web-Scraping – DataC goes one step further to accomplish web-scraping for fetching address from internet. Here users get not only the address but the reference link also from where the address has been scraped by DataC. This helps Users to validate the web-scraped values.
B. Generating JSON – After getting Address found and formatted, Users have a choice to save that in JSON so that data can be passed to any Database for permanent storage.
6. Activation of processed record
With all the above steps, data have been sanitized, de-duplicated, standardized, updated with Address by now. It’s ready for sync with source of truth. DataC gives options here to sync data –
- With Data Governance – SAP MDG can be integrated here – DataC comes with this option as out of box. Users have a choice of integrating with any other Governance tool as well.
- Without Data Governance – Users may sync data directly, should their need be urgent.
DataC comes with a Dashboard to show various insights from the overall process so that Users can remain updated.
You have seen how DataC is helpful in the complex activity of Data Cleansing with AI-Models/algorithms